
Over the Internet various communications such as electronic mail, or the use of world wide web browsers are not secure for sending and receiving information. Information sent by those means may include sensitive personal data which may be intercepted. There is commercial activity going on the Internet and many web sites require the users to fill forms and include sensitive personal information such as telephone numbers, addresses, and credit card information. To be able to do that users would like to have a secure, private communication with the other party. Online users may need private and secure communications for other reasons as well. They may simply not want third parties to browse and read their e-mails or alter their content.
What is Cryptography ?
Cryptography defined as "the science and study of secret writing," concerns the ways in which communications and data can be encoded to prevent disclosure of their contents through eavesdropping or message interception, using codes (2), ciphers (3), and other methods, so that only certain people can see the real message. Although the science of cryptography is very old, the desktop-computer revolution has made it possible for cryptographic techniques to become widely used and accessible to nonexperts. David Kahn traces the history of cryptography from Ancient Egypt into the computer age (4). According to Kahn's research from Julius Caesar to Mary, Queen of Scots (5) to Abraham Lincoln's Civil War ciphers, cryptography has been a part of the history. Over the centuries complex computer-based codes, algorithms and machines were created. During World War I, the Germans developed the Enigma machine to have secure communications (6). Enigma codes were decrypted under the secret Ultra project during World War II by the British.
Why Have Cryptography ?
Encryption is the science of changing data so that it is unrecognisable and useless to an unauthorised person. Decryption is changing it back to its original form. The most secure techniques use a mathematical algorithm and a variable value known as a 'key'. The selected key (often any random character string) is input on encryption and is integral to the changing of the data. The EXACT same key MUST be input to enable decryption of the data. This is the basis of the protection.... if the key (sometimes called a password) is only known by authorized individual(s), the data cannot be exposed to other parties. Only those who know the key can decrypt it. This is known as 'private key' cryptography, which is the most well known form.
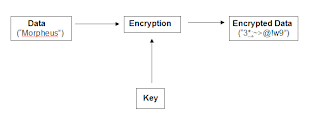
What is Encryption ?
Encryption is basically an indication of users' distrust of the security of the system, the owner or operator of the system, or law enforcement authorities." (7)
Encryption transforms original information, called plaintext or cleartext, into transformed information, called ciphertext, codetext or simply cipher, which usually has the appearance of random, unintelligible data. The transformed information, in its encrypted form, is called the cryptogram. (8)
Encryption algorithm determines how simple or how complex the process of transformation will be (9). Encryption provides confidentiality, integrity and authenticity of the information transferred from A to B. It will be a secret transmission ensuring that its integrity has not been tampered and also it is authentic, that the information was sent by A. All these three points may be important for different reasons for the transmission of data over the Internet (10).
Who needs Cryptography ?
The ability to protect and secure information is vital to the growth of electronic commerce and to the growth of the Internet itself. Many people need or want to use communications and data security in different areas. Banks use encryption methods all around the world (11) to process financial transactions. These involve transfer of huge amount of money from one bank to another. Banks also use encryption methods to protect their customers ID numbers at bank automated teller machines.
"As the economy continues to move away from cash transactions towards "digital cash", both customers and merchants will need the authentication provided by unforgeable digital signatures in order to prevent forgery and transact with confidence." (12)
This is an important issue related to the Internet users. There are many companies and even shopping malls selling anything from flowers to bottles of wines over the Internet and these transactions are made by the use of credit cards and secure Internet browsers including encryption techniques. The customers over the Internet would like to be secure about sending their credit card information and other financial details related to them over a multi-national environment. It will only work by the use of strong and unforgeable encryption methods.
Also business and commercial companies with trade secrets use or would like to use encryption against high-tech eavesdropping and industrial espionage. Professionals such as lawyers, doctors, dentists or accountants who have confidential information throughout their activities will need encryption if they will rely on the use of Internet in the future. Criminals do use encryption and will use it to cover their illegal activities and to make untraceable perfect crimes possible. More important, people need or desire electronic security from government intrusions or surveillance (13) into their activites on the Internet.
Cryptographic Keys: Private and Public More complex ciphers use a secret key to control a long sequence of complicated substitutions (14) and transpositions (15). There are two general categories of cryptographic keys: Private key and public key systems.
Private Key CryptographyPrivate key systems use a single key. The single key is used both to encrypt and decrypt the information. Both sides of the transmission need a separate key and the key must be kept secret from. The security of the transmission will depend on how well the key is protected. The US Government developed the Data Encryption Standard ("DES") which operates on this basis and it is the actual US standard. DES keys are 56 bits (16) long. The length of the key was criticised and it was suggested that the short key was designed to be long enough to frustrate corporate eavesdroppers, but short enough to be broken by the National Security Agency ("NSA") (17). Export of DES is controlled by the State Department. DES system is getting old and becoming insecure. US government offered to replace the DES with a new algorithm called Skipjack which involves escrowed encryption.
Public Key Cryptography
In the public key system there are two keys: a public and a private key. Each user has both keys and while the private key must be kept secret the public key is publicly known. Both keys are mathematically related. If A encrypts a message with his private key then B, the recipient of the message can decrypt it with A's public key. Similarly anyone who knows A's public key can send him a message by encrypting it with his public key. A will than decrypt it with his private key. Public key cryptography was developed in 1977 by Rivest, Shamir and Adleman ("RSA") in the US. This kind of cryptography is more eficient than the private key cryptography because each user has only one key to encrypt and decrypt all the messages that he or she sends or receives.
Endnotes:
1. The word cryptography comes from Greek and kryptos means "hidden" while graphia stands for "writing".
2. A code is a system of communication that relies on a pre-arranged mapping of meanings such as those found in a codebook.
3. A cipher is different from a code and it is a method of encrypting any text regardless of its content.
4. David Kahn, The Codebreakers, Macmillan Company, New York: 1972.
5. Mary, Queen of Scots, lost her life in the 16th century because an encrypted message she sent from prison was intercepted and deciphered.
6. See David Kahn, Seizing the Enigma, Houghton Mifflin, Boston: 1991.
7. Lance Rose, Netlaw: Your Rights in the Online World, Osborne Mc Graw-Hill, 1995, page 182.
8. Deborah Russell and G.T. Gangemi, Sr., "Encryption" from Computer Security Basics, O'Reilly & Associates, Inc., California: 1991, pp 165-179 taken from Lance J. Hoffman, Building in Big Brother: TheCryptography Policy Debate, Spriner-Verlag, New York: 1995, at page 14.
9. ibid.
10. While military and secret services will require a confidential transmission, it will be important for banks to have accurate information of their transactions by electronic means. Authentication technique provides digital signatures which are unique for every transcation and cannot be forged.
11. The U.S. Department of the Treasury requires encryption of all U.S. electronic funds transfer messages. See Gerald Murphy, U.S. Dep't of Treasury, Directive: Electronic Funds and Securities Transfer Policy - Message Authentication and Enhanced Security, No. 16-02, section 3 (Dec. 21, 1992).
12. A. Michael Froomkin, "The Metaphor is the Key: Cryptography, the Clipper Chip and the Constitution" [1995] U. Penn. L. Rev. 143, 709-897, at 720.
13. E.g. the FBI during 1970s wiretapped and bugged the communications of Black Panthers and other dissident groups. See Sanford J. Ungar, FBI 137, (1975). Also between 1953 and 1973, the CIA opened and photographed almost 250000 first class letters within the US from which it compiled a database of almost 1.5 million names. See Church Committee Report, S. Rep. No. 755, 94th Cong., 2d Sess., pt. 2, 1976, at 6.
14. Substitution ciphers replace the actual bits, characters, or blocks of characters with substitutes, eg. one letter replaces another letter. Julius Caesar's military use of such a cipher was the first clearly documented case. In Caesar's cipher each letter of an original message is replaced with the letter three palces beyond it in the alphabet.
15. Transposition ciphers rearrange the order of the bits, characters, or blocks of characters that are being encrypted and decrypted.
16. This means that there are 72 quadrillion different possible keys.
17. See James Bamford, The Puzzle Palace: A Report on America's Most Secret Agency, 1982.





